You're asking too little from your LLM
A recent blog post about "premature closure" with LLMs argues that we're accepting AI suggestions too quickly, leading to missed opportunities and technical debt. The author warns that LLMs give plausible-looking code with subtle flaws, so we need to spend more time reviewing everything they produce.
I think this completely misses the point.
The wrong problem
Yes, LLMs will give plausible answers to basically any question you ask them. But the solution to unreliable AI output isn't to:
- Run a full code review as if your own AI generated code like a peer
- Always ask for alternatives
- Trust but verify by understanding every detail and explaining it to teammates
You can sidestep most of that careful stepping-through-a-minefield experience if you restrict yourself to smaller building blocks. You're still going to read the code, but your experience changes from "I always have to step carefully because every step could have subtle gotchas - how can I trust this is actually good?" to "I'm asking for smaller sub-problems that don't leave room for the AI to introduce subtle mistakes."
There's a specific complexity range where modern LLMs are basically always correct. No subtle bugs, no gotchas, no problems worth worrying about. This reliable range is smaller than what the model can produce, but within it, you can ship with confidence.
Think about it like this: you could ask an LLM to write an entire microservices architecture from scratch, and you'd be disappointed with the result. But ask it to write a function that runs a SQL query or two and puts that information into a specific output struct? It works every time.
The invisible complexity problem
Let's be clear about what complexity actually means: it's the number of constraints you have to satisfy. The number of balls you're keeping in the air. The number of needles you have to thread.
The more complex the problem, the more constraints exist, which means the more context you need to include. All of those constraints need to be present when the LLM tries to solve the problem.
When people get frustrated saying "the LLM made this code change but didn't consider X" - the first question should be: was X present in the context window?
Most of the "subtle issues" people complain about aren't actually LLM failures - they're context failures. The human is judging the output based on information that was visible provided to the LLM.
Here's a thought experiment: imagine you bring a programmer friend from another company to work with you. You get a refrigerator box, tape your friend inside it, and put the box in a conference room. Then you print out the exact API request you were going to send to the LLM - all the context as a string - and slide that paper through a slot.
Will your friend have enough information to give you a good solution?
Now imagine yourself looking at that printout. Picture yourself trapped in the refrigerator box. Are all those code review criticisms you're about to make actually addressable with the information provided? All those points about "how this interacts with other services" or "database performance considerations" - is any of that context available on the paper? Remember, the LLM does not get a screenshot of your IDE with you submit a chat message. All of the information you see at a glance does not exist to the LLM. Only whats on that printout. It's only what you wrote, and what your toolchain included automatically.
If you're judging the output on factors like "the database is small and managed, so it doesn't have many IOPs," was that information anywhere in your request?
This is what I mean about breaking problems down so you're sure the other facts of the system either don't matter, or you've explicitly included the ones that do. You don't want the LLM to start guessing.
Ask for what you actually want
Take this example from the original "Premature Closure" post, where the author claims the LLM generated problematic code:
def send_notifications(user_ids)
user_ids.each do |user_id|
user = User.find(user_id)
NotificationService.deliver(user.email, build_message(user))
end
end
The author points out this has an N+1 query problem and missing error handling. But think about what was probably asked: "write code to send notifications to these users."
This isn't an LLM failure. This is asking too little.
Engineers think "the LLM can handle the simple code change, but if I ask for too much it'll fall over." Wrong. Modern LLMs can easily handle a 50-line function plus 50 lines of detailed comments explaining assumptions, performance implications, and what changes would invalidate this approach.
Here's what you should ask instead, using a general-purpose prompt template:
%% Your original request HERE %%
Write a concise comment in the style of a dutch engineer that tries to communicate any decisions or information not obvious from the code. The following is a list of ideas to consider addressing (it all depends on the change you're making):
- Explain the assumptions you're making about data volume, system load, and performance
- Document what you believe about the system's current capabilities and constraints
- Describe scenarios where this approach would need to be rewritten
- Note any dependencies or external service behaviors you're assuming
- Explain your reasoning to future engineers who might need to modify this code"
- What performance characteristics you expect
- What would break this approach
- What error conditions you're handling
You can build this template and reuse it for any coding task. The proof that this works? Multiple commenters on the original post said they pasted those "problematic" code examples into an LLM, asked what was wrong, and got the right answer immediately. The model has the capability; people just aren't asking for it upfront.
The LLM will document assumptions like "assuming we're notifying ~1000 users" or "assuming the NotificationService can handle individual calls" - revealing exactly the blind spots the original author complained about.
You can build a prompt template for this and reuse it. Ask for the code change plus comprehensive documentation of:
- What assumptions you're making about system behavior
The proof that this works? Multiple commenters on the original post said they pasted those "problematic" code examples into an LLM, asked what was wrong, and got the right answer immediately. The model has the capability - people just aren't asking for it upfront.
Stop underestimating what you can ask for. The models got better. Use that capacity.
The real premature closure
The actual problem happens when you develop patterns that work with one model generation, then stick with them forever.
You learn that certain request types need certain context. You develop reliable patterns. Then a new model comes out with dramatically improved capabilities. Suddenly all your old requests work perfectly, but you never push the boundaries to discover what else is now possible.
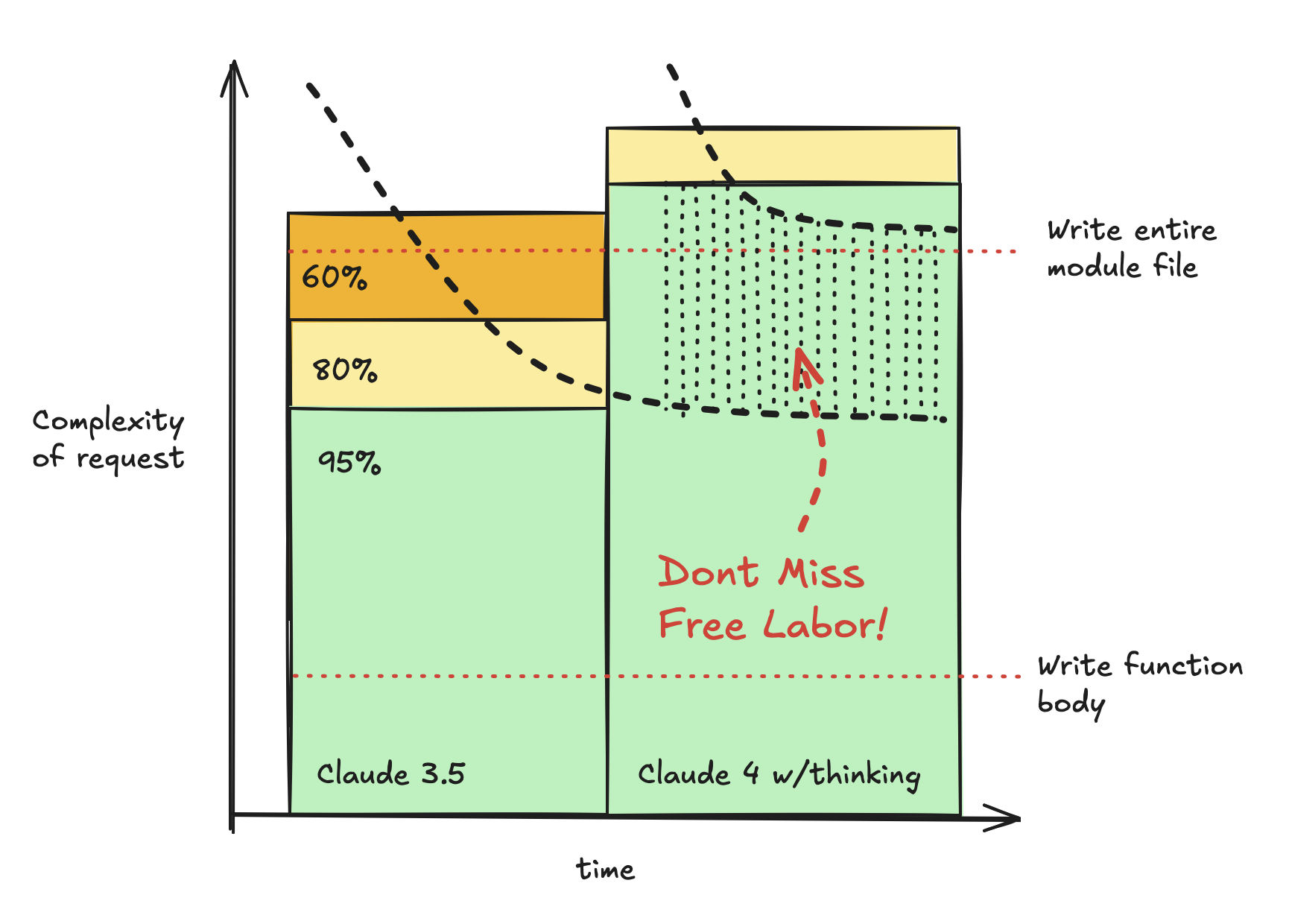
The colored regions show different reliability zones—green is 95%+ success rate, yellow is 80%, orange is 60%. The thick dashed line shows your learning process: you naturally reduce the scope of problems you ask the LLM to solve until you get reliable results consistently.
When model capabilities expand (moving from left to right), the reliability zones shift upward. But if you don't restart your learning process, you keep asking for the same complexity level that worked with the old model. The dotted area represents the free labor you're missing out on—tasks that would now work reliably but that you're not attempting because you haven't recalibrated.
You're leaving productivity on the table because you've prematurely closed your learning process.
Concrete examples
We all know simple API handlers are now trivial. You can say "write a GET handler that takes a resource ID, queries this 10-column table, serializes the result to JSON using our framework, and includes proper error handling." It works perfectly every time.
But remember: this wasn't the case just two years ago! You used to have to carefully specify every detail or the LLM would make up variable names and hallucinate table columns.
Now you can be lazy. Paste in 300 lines of database schema and it will get the column names for the one table you want to use right every time, even if your naming convention is weird. It used to make stuff up. Now it doesn't.
Property-based testing is where this gets interesting. You can now ask an *LLM to write property-based tests and it gets them right. This matters because *there are many ways to "cheat" at writing unit tests, and unit tests often *obscure the real ideas and assumptions behind a module. Property tests operate *at a higher conceptual level.
The real value shows up for complicated code. Say you're writing an optimizing compiler for PyTorch operator fusion. You're breaking invariants temporarily for performance - doing operations out of order, where the path you take determines whether you get the correct result. While you're doing these optimizations, you don't have the normal safety guarantees. You have to carefully restore the invariants before you're done.
You can ask the LLM to write that compiler code, then ask it to write property-based tests in a follow-up message. The LLM understands the invariants just by looking at the data structure. It can write both the implementation that manages the temporary invariant violations and the tests that verify everything works correctly.
Two years ago, this required an engineer with deep expertise and extra time to think through all the edge cases mathematically. Now you just ask for it.
The reliability zone keeps expanding upward. Tasks that required careful engineering thought are moving into the "just works" category.
How to calibrate properly
Here's what effective LLM usage actually looks like:
- Experiment with scope: Try increasingly complex requests until you find the failure boundary
- Find the sweet spot: Identify the complexity level that works 95%+ of the time
- Build patterns: Develop consistent ways to structure requests at that level
- Model upgrade: New model releases with improved capabilities
- Restart the cycle: The old "too complex" requests now work reliably
Most engineers stop at step 3. They find what works and stick with it, even as capabilities improve dramatically.
This isn't about being careful
The original article suggests we need more careful review of LLM output. I think that's exactly backwards.
Stop worrying about reviewing every output for subtle flaws. Instead, learn to calibrate your request scope so you're working in the reliability zone. And when capabilities improve, restart your calibration process.
The engineers getting extraordinary results aren't the ones who found safe patterns and stuck with them. They're the ones who continuously push boundaries and recalibrate with each improvement.
The biggest waste isn't the occasional failed prompt—it's the months of productivity you miss by not discovering what's now possible.